P(Processor):即为 G 和 M 的调度对象,用来调度 G 和 M 之间的关联关系,其数量可通过 GOMAXPROCS()来设置,默认为核心数。
3. 1.0 之前 GM 调度模型
调度器把 G 都分配到 M 上,不同的 G 在不同的 M 并发运行时,都需要向系统申请资源,比如堆栈内存等,因为资源是全局的,就会因为资源竞争照成很多性能损耗。为了解决这一的问题 go 从 1.1 版本引入,在运行时系统的时候加入 p 对象,让 P 去管理这个 G 对象,M 想要运行 G,必须绑定 P,才能运行 P 所管理 的 G。
单一全局互斥锁(Sched.Lock)和集中状态存储
Goroutine 传递问题(M 经常在 M 之间传递”可运行”的 goroutine)
每个 M 做内存缓存,导致内存占用过高,数据局部性较差
频繁 syscall 调用,导致严重的线程阻塞/解锁,加剧额外的性能损耗。
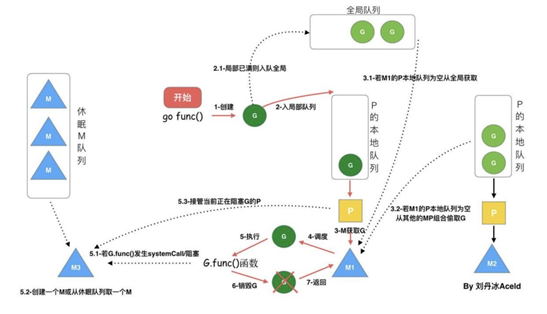
4. GMP 调度流程
⚫ 每个 P 有个局部队列,局部队列保存待执行的 goroutine(流程 2),当 M 绑 定的 P 的的局部队列已经满了之后就会把 goroutine 放到全局队列(流程 2- 1)
⚫ 每个 P 和一个 M 绑定,M 是真正的执行 P 中 goroutine 的实体(流程 3),M 从绑定的 P 中的局部队列获取 G 来执行
⚫ 当 M 绑定的 P 的局部队列为空时,M 会从全局队列获取到本地队列来执行G(流程 3.1),当从全局队列中没有获取到可执行的 G 时候,M 会从其他 P 的局部队列中偷取 G 来执行(流程 3.2),这种从其他 P 偷的方式称为 work stealing
⚫ 当 G 因系统调用(syscall)阻塞时会阻塞 M,此时 P 会和 M 解绑即 hand off,并寻找新的 idle 的 M,若没有 idle 的 M 就会新建一个 M(流程 5.1)。
⚫ 当 G 因 channel 或者 network I/O 阻塞时,不会阻塞 M,M 会寻找其他 runnable 的 G;当阻塞的 G 恢复后会重新进入 runnable 进入 P 队列等待执 行(流程 5.3)
5. GMP 中 work stealing 机制
存到 P 本地队列或者是全局队列。P 此时去唤醒一个 M。P 继续执行它的执行序。M 寻找是否有空闲的 P,如果有则将该 G 对象移动到它本身。接下来 M 执行一个调度循环(调用 G 对象->执行->清理线程→继续找新的 Goroutine 执行)。
6. GMP 中 hand off 机制
当本线程 M 因为 G 进行的系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的 M’执行。当发生上线文切换时,需要对执行现场进行保护,以便下次被调度执行时进行现场恢复。Go 调度器 M 的栈保存在 G 对象上,只需要将 M 所需要的寄存器(SP、PC 等)保存到 G 对象上就可以实现现场保护。当这些寄存器数据被保护起来,就随时可以做上下文切换了,在中断之前把现场保存起来。如果此时 G 任务还没有执行完,M 可以将任务重新丢到 P 的任务队列,等待下 一次被调度执行。当再次被调度执行时,M 通过访问 G 的 vdsoSP、vdsoPC 寄存器进行现场恢复(从上次中断位置继续执行)。
7. 协作式的抢占式调度
在 1.14 版本之前,程序只能依靠 Goroutine 主动让出 CPU 资源才能触发调度,存在问题
在任何情况下,Go 运行时并行执行(注意,不是并发)的 goroutines 数量是小于等于 P 的数量的。为了提高系统的性能,P 的数量肯定不是越小越好,所以官方默认值就是 CPU 的核心数,设置的过小的话,如果一个持有 P 的 M, 由于 P 当前执行的 G 调用了 syscall 而导致 M 被阻塞,那么此时关键点:GO 的调度器是迟钝的,它很可能什么都没做,直到 M 阻塞了相当长时间以后,才会发现有一个 P/M 被 syscall 阻塞了。然后,才会用空闲的 M 来强这个 P。通过 sysmon 监控实现的抢占式调度,最快在 20us,最慢在 10-20ms 才 会发现有一个 M 持有 P 并阻塞了。操作系统在 1ms 内可以完成很多次线程调度(一般情况 1ms 可以完成几十次线程调度),Go 发起 IO/syscall 的时候执行该 G 的 M 会阻塞然后被 OS 调度走,P 什么也不干,sysmon 最慢要 10-20ms才能发现这个阻塞,说不定那时候阻塞已经结束了,宝贵的 P 资源就这么被阻塞的 M 浪费了。